Fwd: Stunnel Performance strangeness

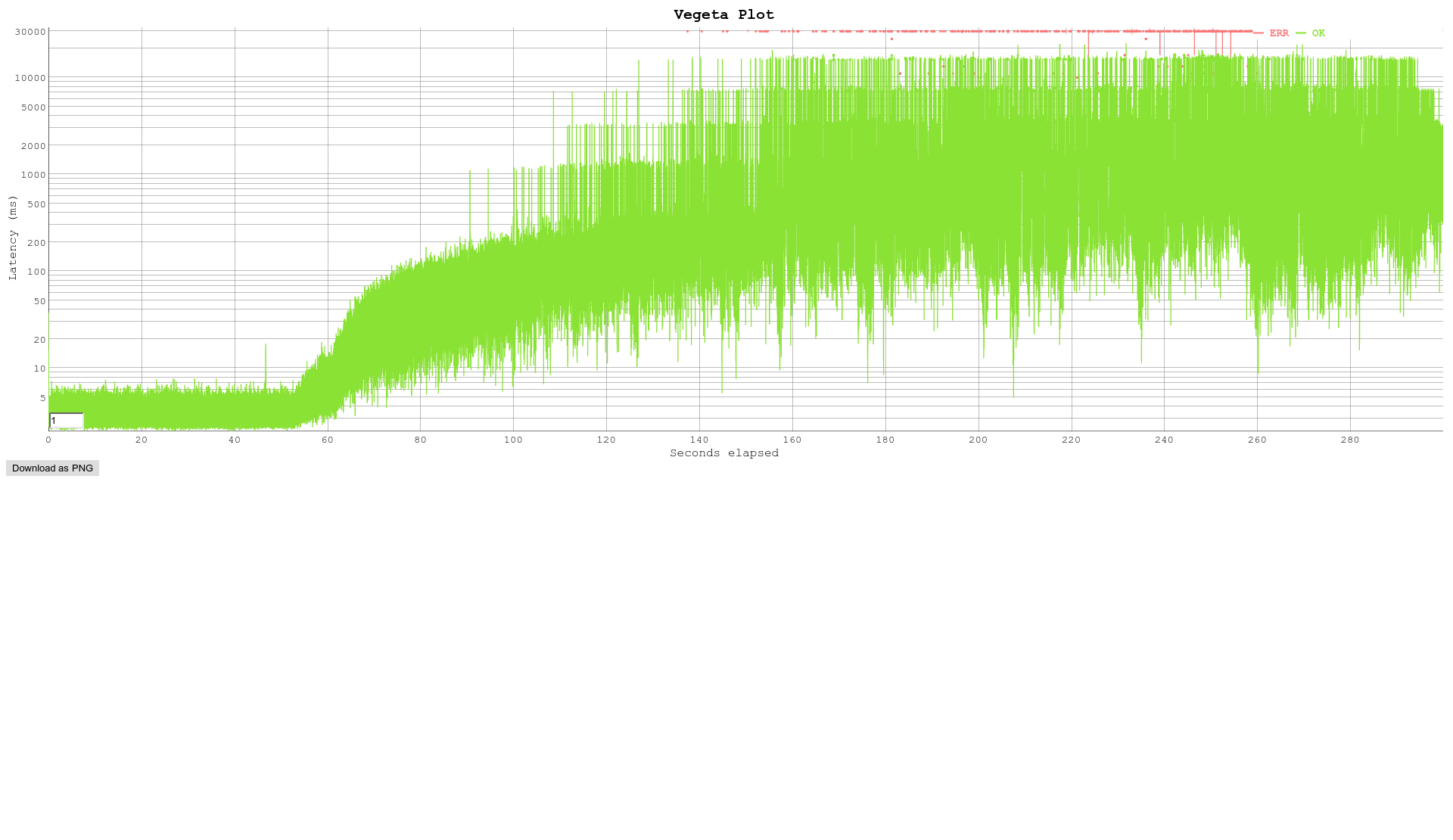
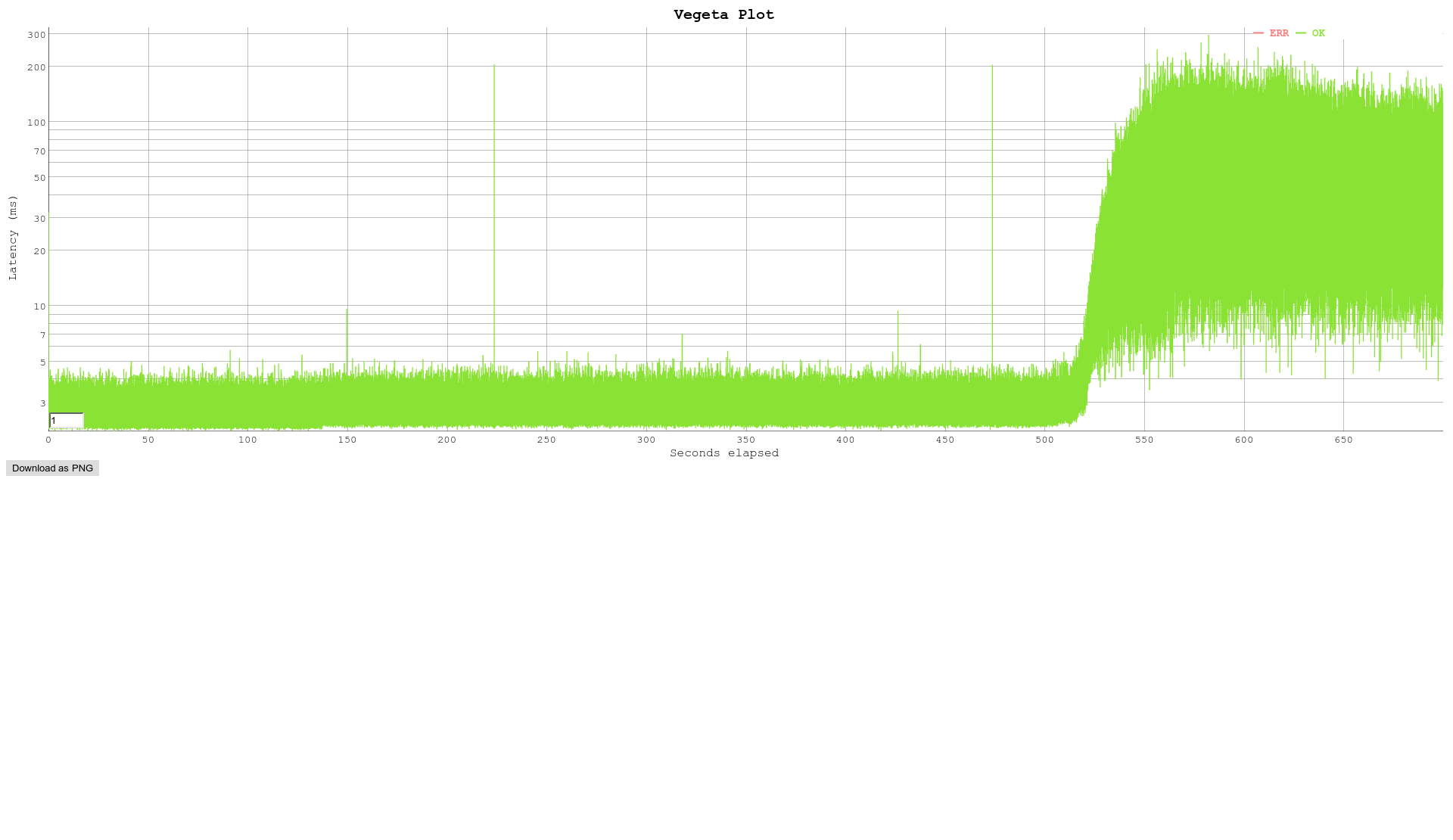
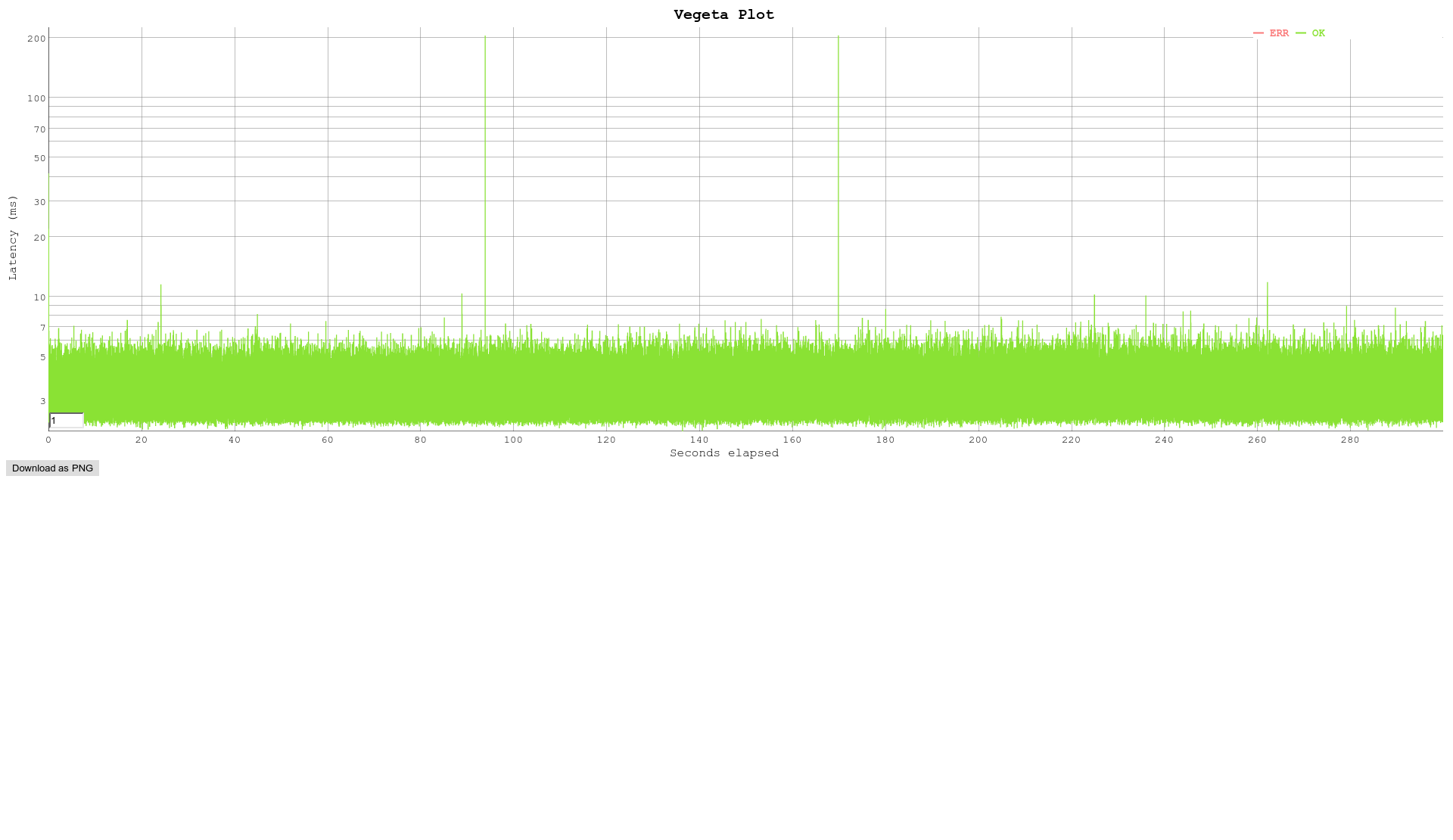
Hi All, We have been doing some throughput testing and are wondering of you can help explain some of the results we have been getting. We are trying to establish the maximum number of handshakes per second our appliances can do when using Stunnel. Our tests have been done on a 4 core Intel(R) Xeon(R) CPU E3-1230 v5 @ 3.40GHz machine with 8Gb ram. Using stunnel 5.33 openssl 1.0.2j (We use stunnel 5.33 here, but this was also tested with stunnel 5.40 and we got the same issue) Stunnel was compiled with - ./configure --enable-fips --enable-ipv6 --with-threads=pthread --sysconfdir=/etc --with-ssl=/usr/src/built/OpenSSL_1_0_2j-no_march/usr/local/ --disable-libwrap --disable-systemd I was using a python script of my own design for load testing when I noticed the problem we then switched to an open source package called vegeta https://github.com/tsenart/vegeta the command I was using to run it was - echo "GET https://10.10.10.10:443" | ./vegeta attack -workers=30 -rate=3000 -duration=300s -insecure > test.out We are essentially seeing a degradation in throughput at a fixed point in time. I am seeing the problem when using 3000 transactions per second. We are doing https gets through stunnel to a http backend, 1 transaction is an ssl handshake the http get and waiting for the response. Interestingly if I try 5.06 it works fine I get a smooth constant loading. Please take a look at 30worker3000rate5.33-300s.png where you can see after about 55 seconds there is a jump in latency. I get the same issue if I run the test with 2000 transactions. Please see 30worker20005.33-700s.png but with the lower transaction rate the issue takes longer to rear its head. The issue doesnt happen if I run the test with 3000 transaction using 5.06. Please see 30worker3000rate5.06-300s.png
From looking at the graphs our thoughts were that we were hitting some sort of cache limit and used that as a starting point. We have taken a look at the code changes between versions we know were working and the problematic version and the main thing that stands out is the changes to the leak detection. Previously this was partially based on the number of clients but has been changed to use the sections. This led to the decision to try a different limit value and found the number of connections we saw before seeing an issue corresponds to the change of the limit value.
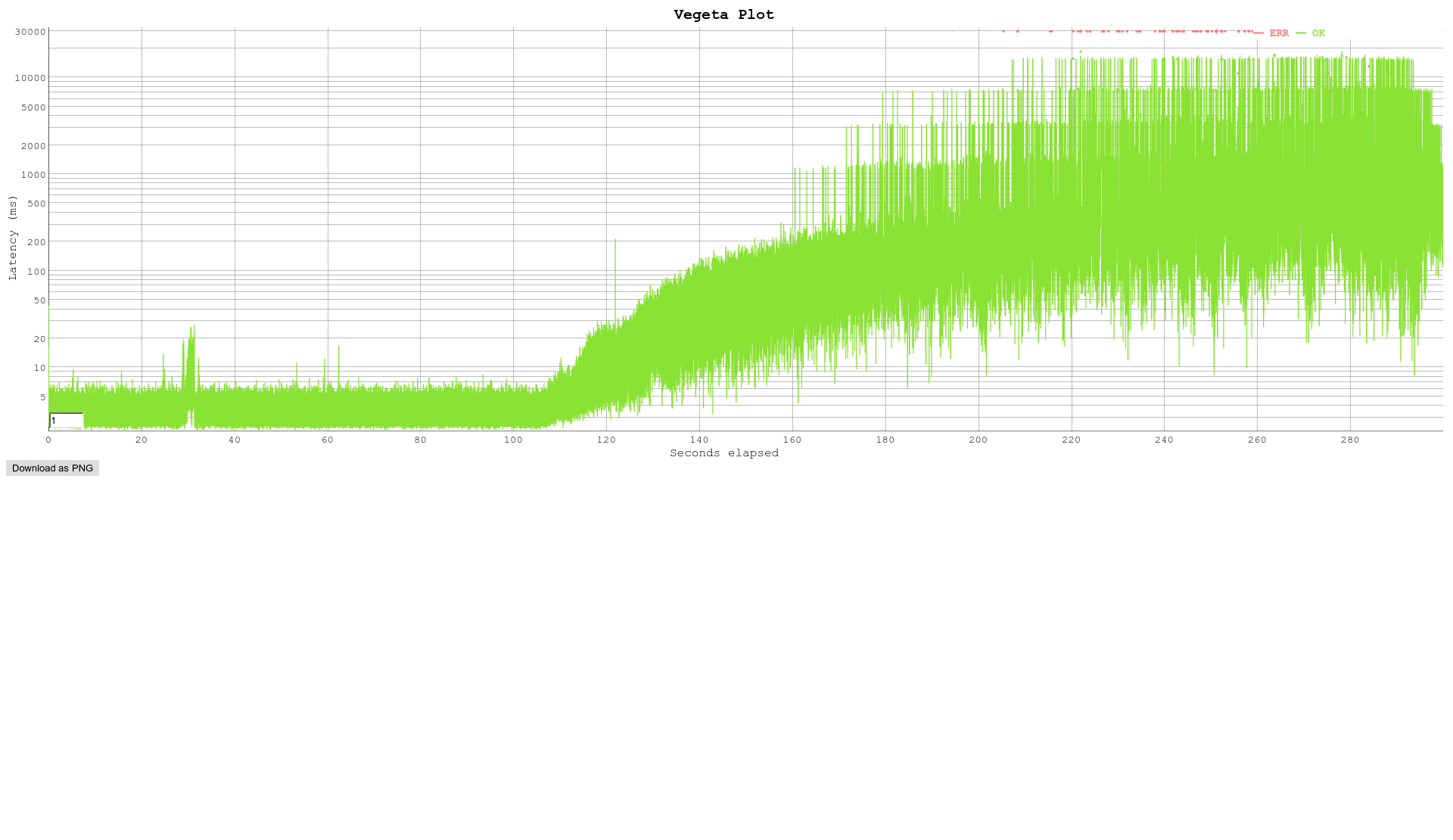
We think we have identified the code that is causing the problem/doing something funny it was added in 5.33 NOEXPORT long leak_threshold() { long limit; limit=10000*((int)number_of_sections+1); #ifndef USE_FORK limit+=100*num_clients; #endif return limit; } its src/str.c when increasing the limit number so limit=10000*((int)number_of_sections+1) to limit=20000*((int)number_of_sections+1) This still results in an increase in response time but at a later time in the test, please see 30worker3000rate5.33-ben-highlimit.png Interestingly once I end up in this state I am stuck with high latencies until I restart stunnel. (The box I am testing on was left over night to make sure its not any hanging tcp connections or anything like that) I must admit we are at the limit of our C understanding and your imput would be welcomed. -- With Kind Regards. Scott McKeown Loadbalancer.org http://www.loadbalancer.org Tel (UK) - +44 (0) 3303801064 <0330%20380%201064> (24x7) Tel (US) - +1 888.867.9504 <+1%20888-867-9504> (Toll Free)(24x7)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
participants (1)
-
 Scott McKeown
Scott McKeown